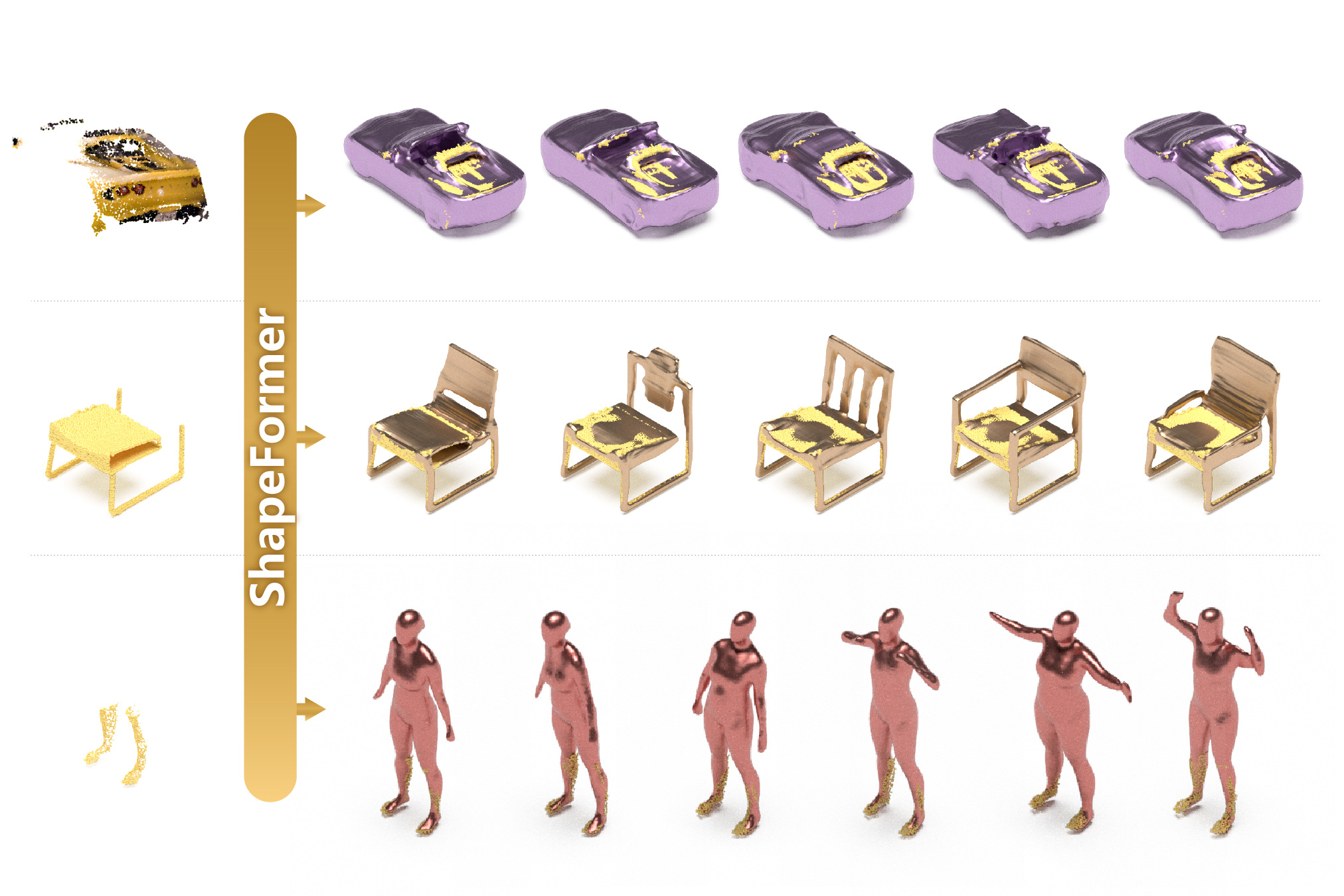
We present ShapeFormer, a transformer-based network that produces a distribution of object completions, conditioned on incomplete, and possibly noisy, point clouds. The resultant distribution can then be sampled to generate likely completions, each of which exhibits plausible shape details, while being faithful to the input.
To facilitate the use of transformers for 3D, we introduce a compact 3D representation, vector quantized deep implicit function (VQDIF), that utilizes spatial sparsity to represent a close approximation of a 3D shape by a short sequence of discrete variables.
Experiments demonstrate that ShapeFormer outperforms prior art for shape completion from ambiguous partial inputs in terms of both completion quality and diversity. We also show that our approach effectively handles a variety of shape types, incomplete patterns, and real-world scans.
We show how our model pre-trained on ShapeNet can be applied to scans of real objects. We test our model on partial point clouds converted from RGBD scans of the Redwood 3D Scans.
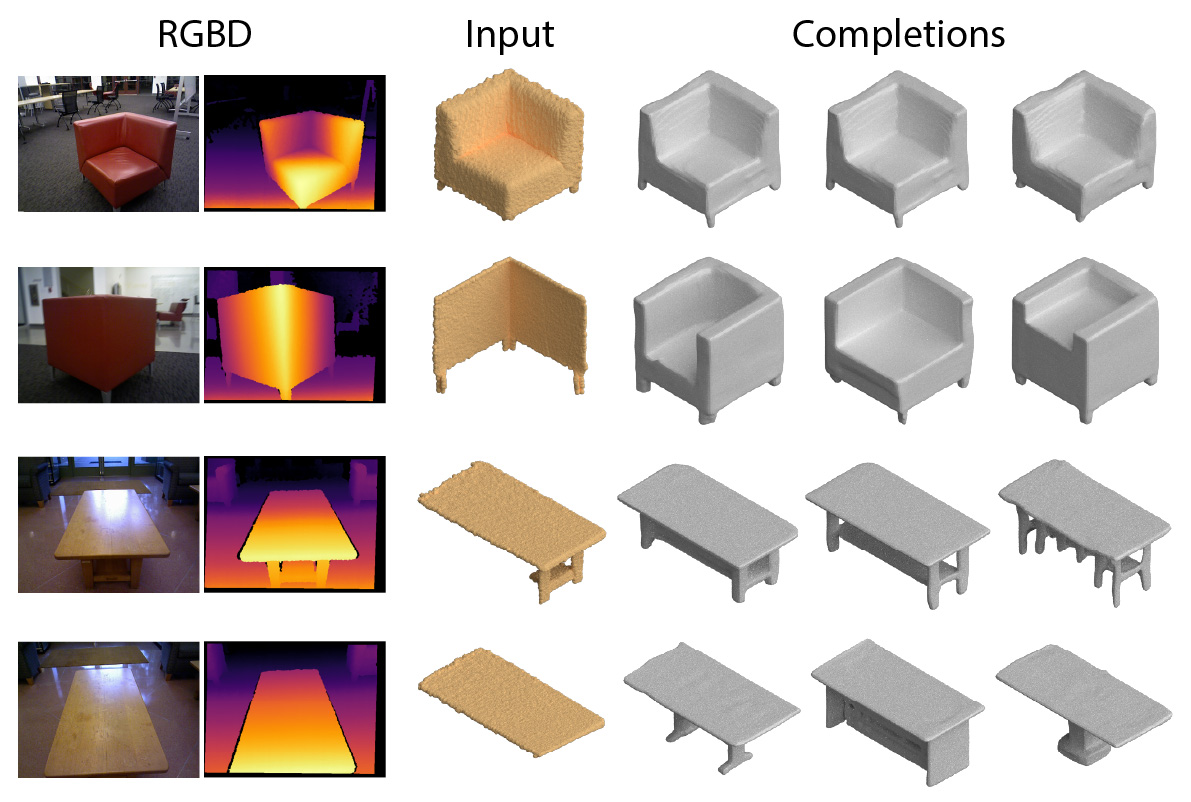
Given a scan of an unseen type of shape, ShapeFormer can produce multiple reasonable completions by generalizing the knowledge learned in the training set.

|
|
|
|
|
|
|
|
|
|
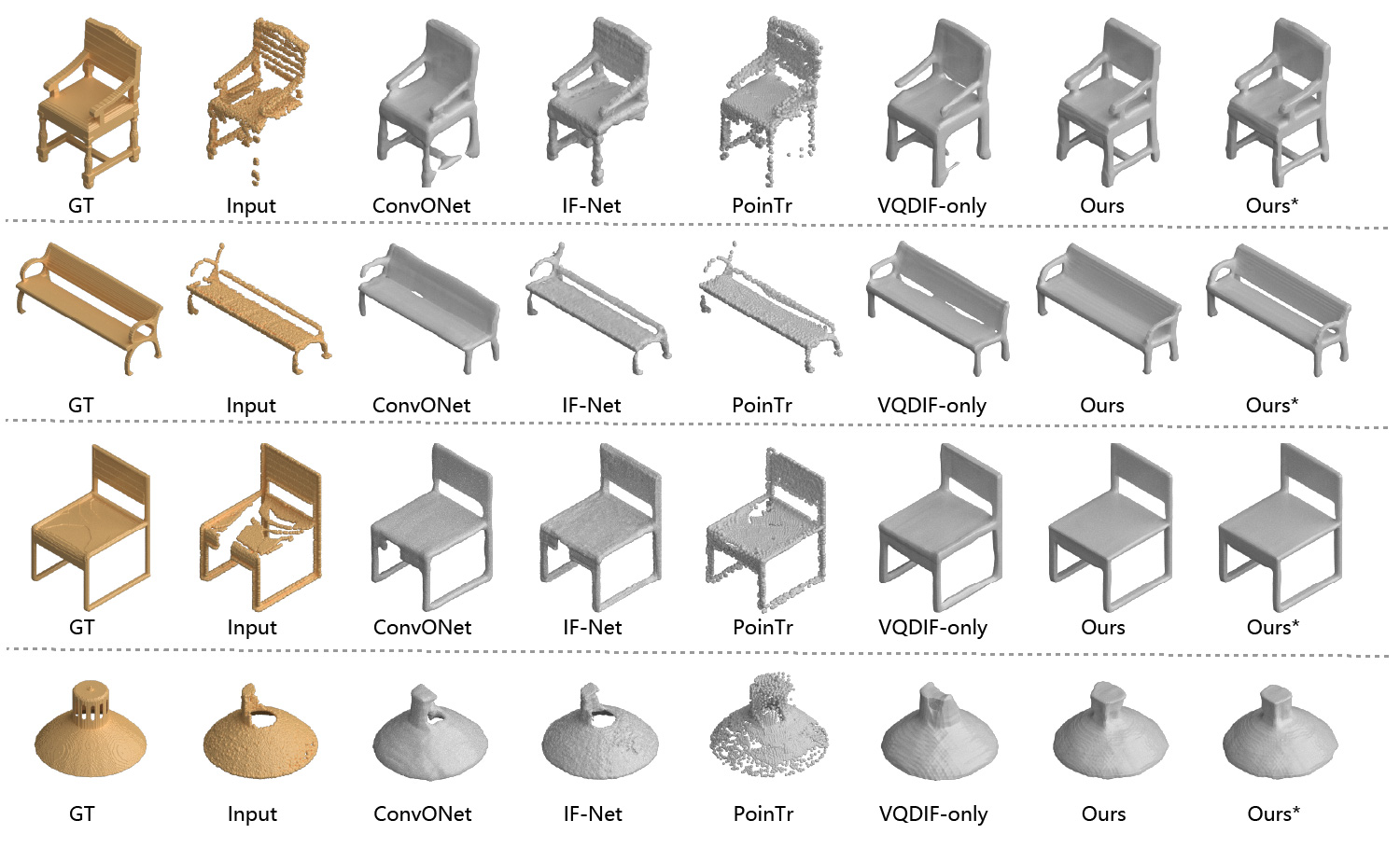
Compared with previous methods, ShapeFormer can better handle ambiguous scans and produce completions that are more faithful on both observed and unseen regions

We further demonstrate our method can achieve competitive accuracy for low-ambiguity scans. Since there is limited ambiguity for such scans and the goal is to achieve accuracy toward ground truth, we put the ground truth in the first row and only sample one single completion.
@inproceedings{yan2022shapeformer,
title={ShapeFormer: Transformer-based Shape Completion via Sparse Representation},
author={Xingguang Yan and Liqiang Lin and Niloy J. Mitra and Dani Lischinski and Danny Cohen-Or and Hui Huang},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2022}
}